Gaze-Tracker
Building light weight eye trackers for mobile devices using simple Convolutional Neural Networks. This repo contains the work done during GSoC-2022 under @INCF.
Gaze-Tracker
Introduction
This year during the GSoC’22 I worked on the Gaze Track project from last year, which is based on the implementation, fine-tuning and experimentation of Google’s paper Accelerating eye movement research via accurate and affordable smartphone eye tracking.
Eye tracking can be used for a range of purposes, from improving accessibility for people with disabilities to improving driver safety. However, modern state-of-the-art mobile eye trackers are costly, often bulky devices that require careful setup and calibration, and they tend to be expensive. The aim of this project therefore is to develop an affordable and open source alternative to these Eye Trackers.
My main task during the GSoC period was the implement the model architecture proposed by Google, in Tensorflow, run SVR experiments, and compare the results to Abhinav’s and Dinesh’s versions. Please refer to the the posts by them on their implementation.
Dataset
Every trained model offered in this project was developed using data from a portion of the enormous MIT GazeCapture dataset, which was made available in 2016. The dataset can be accessed by registering on the website. They include JSON files with the corresponding images that contain information such as bounding box coordinates for the eyes, faces, and other features, as well as data on the number of frames, face detections, and eye detections.
The official GazeCapture repository provides excellent explanations of the dataset’s file structure and the information it contains.
Splits
Only those frames with valid face and eye detections are included in the final dataset. The frame is discarded if any one of the detections is absent.
Therefore, after applying the following filters, our dataset is generated.
- Only Phone Data
- Only portrait orientation
- Valid face detections
- Valid eye detections
After the conditions listed above are satisfied, overall there are 501,735 frames from 1,241 participants.
For the base model training, there are two types of splits that are considered.
MIT Split
Similar to how GazeCapture does it, the MIT Split keeps the train/test/validation split at the per-participant level. This means that a participant’s data does not appear in more than one of the train, test, or validation set. This helps the model to train and generalize more, since the same person does not appear in all the splits.
The details regarding the split are as follows
| Train/Validation/Test | Number of Participants | Total Frames |
|---|---|---|
| Train | 1,075 | 427,092 |
| Validation | 45 | 19,102 |
| Test | 121 | 55,541 |
Google split
The unique ground truth points were used by Google to split their dataset. This means that each participant’s frames are included in the train test and validation sets.
The details regarding the split are as follows
| Train/Validation/Test | Number of Participants | Total Frames |
|---|---|---|
| Train | 1,241 | 366,940 |
| Validation | 1,219 | 50,946 |
| Test | 1,233 | 83,849 |
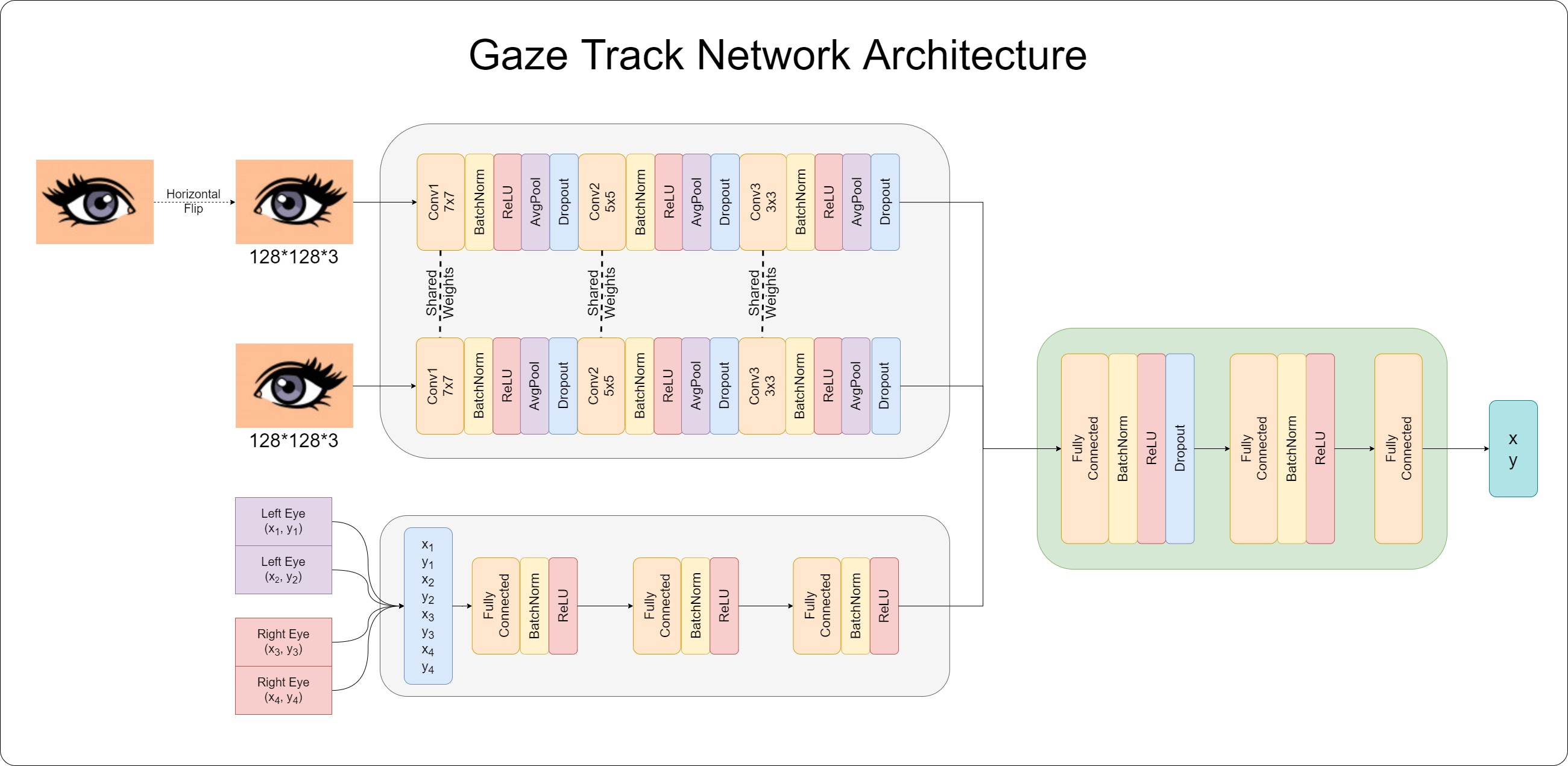
The Network
Using Tensorflow we reproduce the neural network architecture as provided in the Google paper and the supplementary information.
The network architecture is depicted in the diagram below.
Training
The model binary we got from google, whose pipeline we are trying to implement is in .tflite format and takes in data in form of TF Records. So we first build .tfrecs of our data to feed into the model.
When our trained model will be converted to tflite version, there is a possibility of significant accuracy drop. This can be avoided by post-training quantization using the Tensorflow pipeline itself, implemented very similar to Google’s pipeline.
I used the Reduce LR on Plateau learning rate scheduler. Experiments were carried out with Exponential LR, Reduce LR on Plateau and no LR schedulers. Reduce LR on Plateau gave the best results. This is opposite to Abhinav’s & Dinesh’s PyTorch versions.
The loss we used was Mean Squared Error (MSE) and metric Mean Euclidean Distance (MED) was defined as
def mean_euc(a, b):
euc_dist = np.sqrt(np.sum(np.square(a - b), axis=1))
mean_euc = euc_dist.mean()
return mean_euc
Results
Base model results -
We compare our results with that of Dinesh’s(Pytorch implementation from last year) and Abhinav’s(PyTorch Implementation, with changes in hyperparameters).
| Split | TF Implementation | Dinesh’s | Abhinav’s |
|---|---|---|---|
| MIT | 2.03cm | 2.03cm | 2.06cm |
| 1.80cm | 1.86cm | 1.68cm |
Following the Tensorflow pipeline we’re able to get comparable results. This would be useful later when we compare our own tflite version with the tflite binary provided by Google.
TF model checkpoints are available on the project repository.
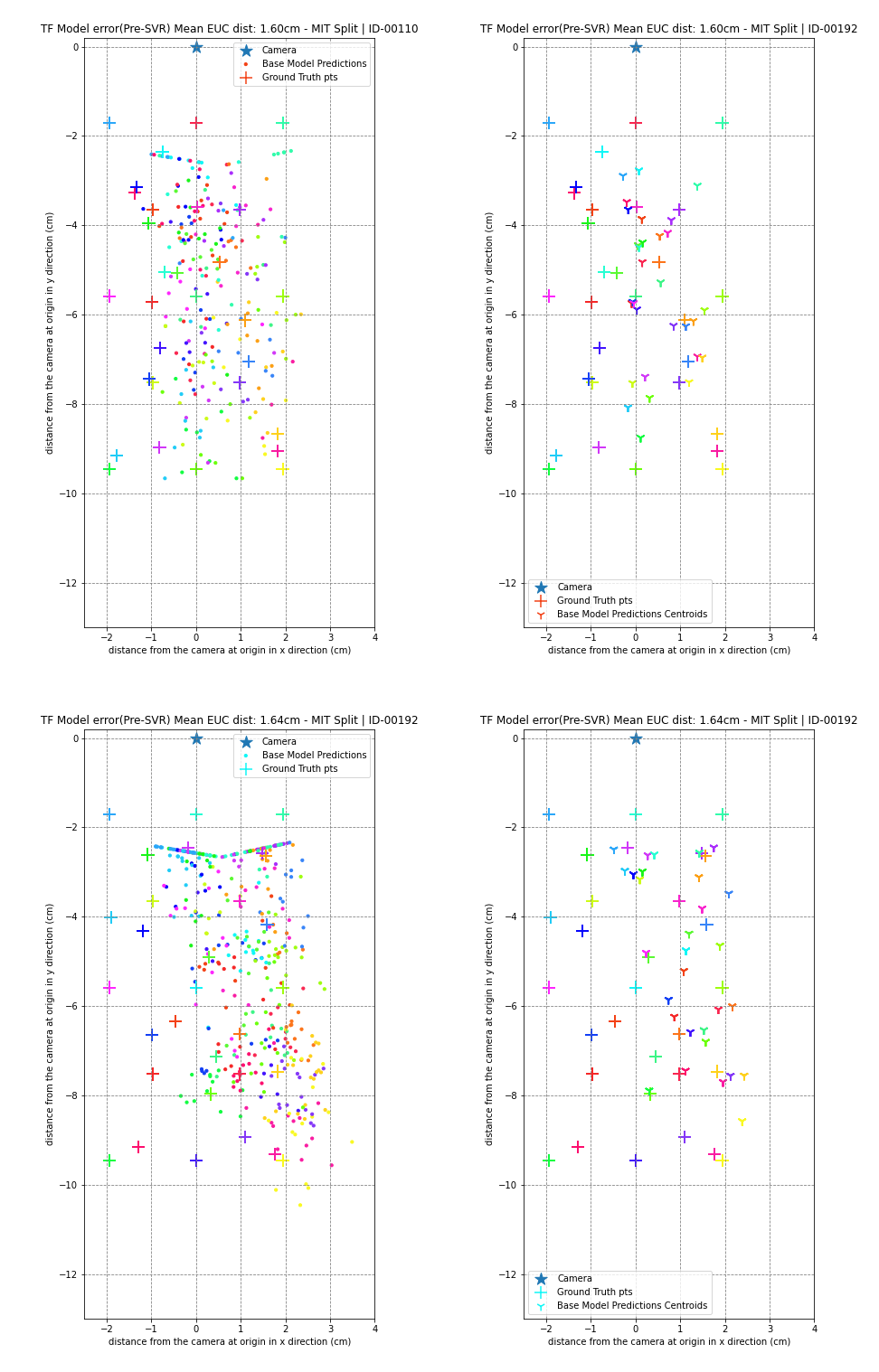
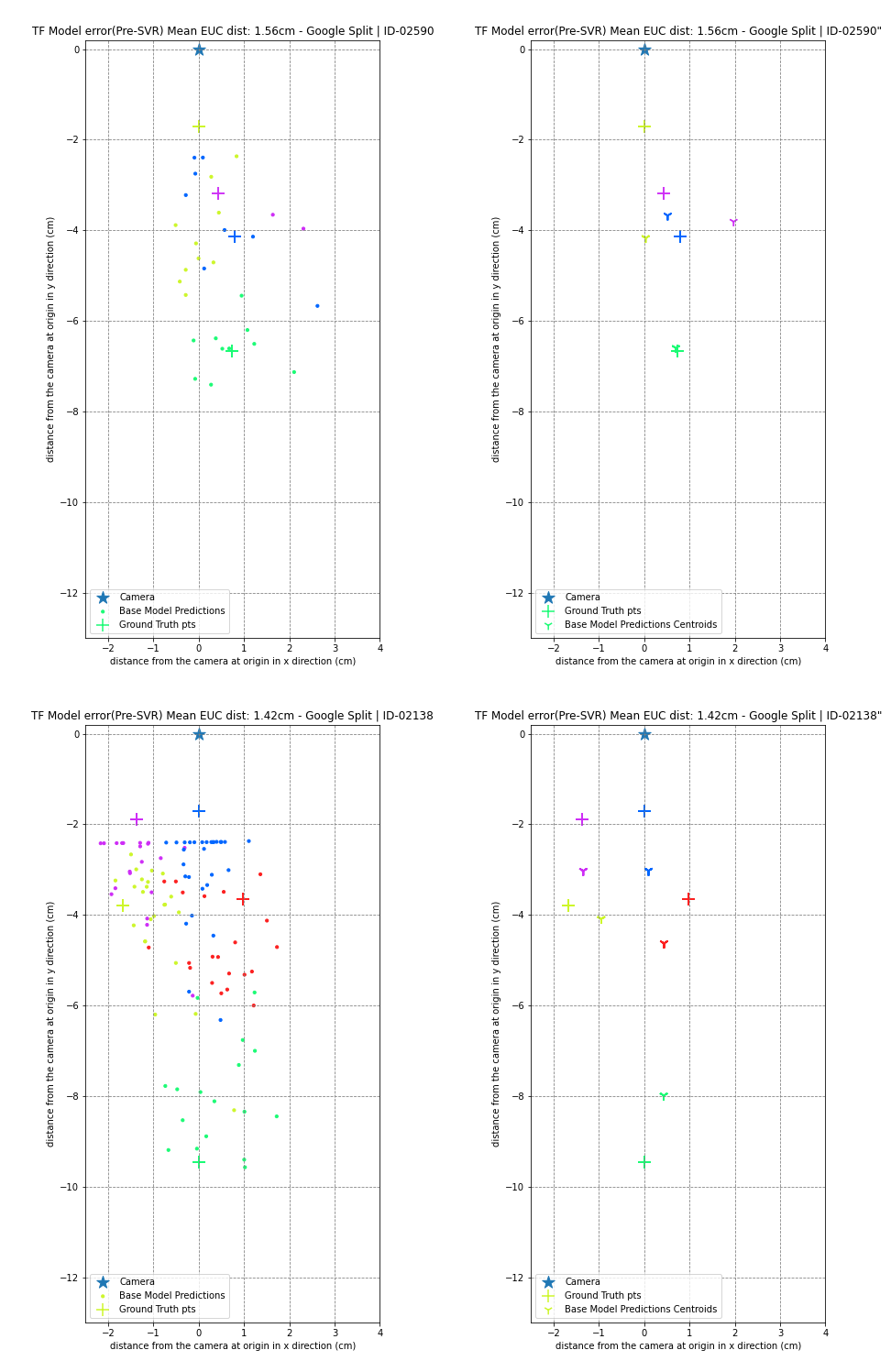
Here are some of the visualizations of gaze predictions from this years Tensorflow Implementation.
The ‘+’ signs are the ground truth gaze locations, Dots are base model predictions and Tri-Downs are mean of base model predictions for that particular ground truth gaze location. Each gaze location has several frames connected to it, and as a result, has several predictions. We apply colour coding to correlate predictions to their corresponding ground truth. All dots and tri-ups of a color correspond to the ‘+’ of the same color. The star(*) corresonds to the camera position, which is at the origin.
MIT Split
Google Split
SVR Implementation
The next task was to compare the SVR results with the current implementations. Google, in their pipeline extracts the output of shape (1,4) from the penultimate layer of the multilayer feed-forward convolutional neural network (CNN), and fits it at a per-user-level to build a high-accuracy personalized model. We follow the same.
For the purpose of getting the output of the penultimate layer, a hook is attached to the model. A multioutput regressor SVR is used once the output of shape (x,4) from the penultimate layer has been obtained. This was fitted on the test set of the trained model.
For sweeping the parameters of SVR, we consider:
- kernel=’rbf’
- C=20
- gamma=0.6
This is similar to what Google stated in their supplementary material.
To select the best value, the epsilon value of the Multioutput Regressor was swept between 0.01 and 1000. For the purpose of fitting the SVR, the test set is divided into two ratios: 70:30 and 2/3:1/3. We then perform 3 fold and 5 fold grid search. Using this we obtain the best parameter for each individual, which is used to fit the SVR.
Various Splits for SVR
There are two within-individual SVR personalization versions -
- On Google Split - Individuals from the base model train set are including in the train/test set for SVR. This is not very practical since there is data leakage, and therefore will also results in minimum errors compared to other splits.
- On MIT Split - Individuals from the base model train set are not included in the train/test set for SVR. This is more practical.
Within both these versions, there are two sub-versions
- On Unique Ground Truth values - We split the whole set into train and test, based on unique ground truth values. This results in both the sets having different ground truth values. More specifically, we randomly pick out one frame corresponding to each ground truth value, and hence there are 30 frames in the set as there are 30 unique Ground truth values.
- On Random Data points/samples - We split the whole set into train and test, randomly, which results in data points coming from all screen positions in both both the sets.
The Unique Ground Truth values version corresponds more to the real life scenario since the random Data Points version may have very similar samples in both the train and test sets, which would result in poor generalization.
Another split we tried is the No Shuffle split, where we use, say first 70% of the test set points for fitting the SVR, and the latter 30% for testing the SVR. This also corresponds to the actual use-case, where we first calibrate the SVR, and then the subject uses the model.
We select 10 users based on the highest number of frames from each of the above mentioned splits. This is the data that the base model has not seen, and so SVR is fitted on them.
MIT Split
1. Mean Results Comparison
Base-model Results:
| Implementation | MED |
|---|---|
| Abhinav’s | 1.82cm |
| New(TF) | 1.68cm |
Post-SVR Results:
- Random Data points/samples (All Frames)
| Implementation | 70 & 30 split | 2/3 & 1/3 split | ||
|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |
| Abhinav’s | 1.46cm | - | - | - |
| New(TF) | 1.48cm | 1.69cm | 1.49cm | 1.64cm |
- Unique Ground Truth values (30 points)
| Implementation | 70 & 30 split | 2/3 & 1/3 split | ||
|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |
| Abhinav’s | 1.76cm | - | - | - |
| New(TF) | 1.73cm | 1.75cm | 1.84cm | 1.72cm |
Base Model MED vs Post SVR MED:
- Random Data points/samples (All Frames)
| Version | 70 & 30 split | 2/3 & 1/3 split | ||
|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |
| TF Base Model MED | 1.79cm | 1.88cm | 1.79cm | 1.86cm |
| Post SVR MED | 1.48cm | 1.69cm | 1.49cm | 1.64cm |
- Unique Ground Truth values (30 points)
| Version | 70 & 30 split | 2/3 & 1/3 split | ||
|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |
| TF Base Model MED | 1.78cm | 1.75cm | 1.83cm | 2cm |
| Post SVR MED | 1.73cm | 1.75cm | 1.84cm | 1.72cm |
2. Per-Individual Comparison:
- Random Data points/samples (All Frames)
| User ID | No. of frames | Base Model MED(Mean across all versions) | SVR-3CV (70&30) | SVR-3CV (2/3&1/3) | ||
|---|---|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |||
| 3183 | 874 | 1.38cm | 1.34cm | 1.42cm | 1.35cm | 1.32cm |
| 1877 | 860 | 2.03cm | 1.28cm | 1.13cm | 1.32cm | 1.09cm |
| 1326 | 784 | 1.53cm | 1.31cm | 1.47cm | 1.29cm | 1.44cm |
| 3140 | 783 | 1.54cm | 1.54cm | 1.44cm | 1.56cm | 1.45cm |
| 2091 | 788 | 1.70cm | 1.80cm | 1.98cm | 1.81cm | 1.92cm |
| 2301 | 864 | 1.86cm | 1.36cm | 1.75cm | 1.34cm | 1.69cm |
| 2240 | 801 | 1.46cm | 1.24cm | 1.52cm | 1.23cm | 1.46cm |
| 382 | 851 | 2.38cm | 2.44cm | 2.89cm | 2.44cm | 2.75cm |
| 2833 | 796 | 1.71cm | 1.68cm | 1.86cm | 1.67cm | 1.87cm |
| 2078 | 786 | 1.24cm | 0.82cm | 1.42cm | 0.83cm | 1.37cm |
- Unique Ground Truth values (30 points)
| User ID | SVR-3CV (70&30) | SVR-3CV (2/3&1/3) | ||
|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |
| 3183 | 1.83cm | 0.85cm | 1.88cm | 1.58cm |
| 1877 | 1.82cm | 1.46cm | 1.64cm | 1.47cm |
| 1326 | 2.39cm | 2.10cm | 2.12cm | 2.09cm |
| 3140 | 1.20cm | 1.30cm | 1.73cm | 1.58cm |
| 2091 | 1.81cm | 1.99cm | 1.94cm | 1.73cm |
| 2301 | 1.43cm | 1.50 | 1.77cm | 1.61cm |
| 2240 | 1.26cm | 1.62cm | 1.16cm | 1.73cm |
| 382 | 2.43cm | 2.52cm | 2.69cm | 2.39cm |
| 2833 | 1.82cm | 1.82cm | 1.89cm | 1.79cm |
| 2078 | 1.27cm | 1.28cm | 1.09cm | 1.20cm |
Analysis
We can see that the mean losses when considering all the frames are lower, compared to the unique ground truth values version. This is due to data leakage as discussed previously. We also notice that the overall mean errors post SVR is significantly lower than that of base model errors. When we don’t shuffle the set during split, the loss increases, since it mimics the real life scenario when the user might look at new ground truth points. When we consider frames with unique ground truth values, the errors per individual are varying a lot, which results in almost similar mean errors. Since this was only trained on 30 frames, the SVR has not generalized well, and possibly learned some unwanted features. This will be cleaned out in the future work.
Google Split
1. Mean Results Comparison
Base-model Results:
| Implementation | MED |
|---|---|
| Abhinav’s | 1.15cm |
| New(TF) | 1.24cm |
Base Model MED vs Post SVR MED:
- Random Data points/samples (All Frames)
| Version | 70 & 30 split | 2/3 & 1/3 split | ||
|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |
| TF Base Model MED | 1.31cm | 1.31cm | 1.32cm | 1cm |
| Post SVR MED | 1.04cm | 1.14cm | 1.12cm | 1.04cm |
2. Per-Individual Comparison:
| User ID | No. of frames | Base Model MED(Mean across all versions) | SVR-3CV (70&30) | SVR-3CV (2/3&1/3) | ||
|---|---|---|---|---|---|---|
| Shuffle = True | Shuffle = False | Shuffle = True | Shuffle = False | |||
| 503 | 965 | 1.38cm | 1.37cm | 1.35cm | 1.32cm | 1.41cm |
| 1866 | 1018 | 1.34cm | 0.86cm | 1.24cm | 1.18cm | 0.88cm |
| 2459 | 1006 | 1.48cm | 0.69cm | 0.81cm | 0.81cm | 0.68cm |
| 1816 | 989 | 1.04cm | 0.92cm | 0.93cm | 0.92cm | 0.94cm |
| 3004 | 983 | 1.22cm | 1.18cm | 1.07cm | 1.05cm | 1.16cm |
| 3253 | 978 | 1.26cm | 0.84cm | 1.07cm | 0.98cm | 0.84cm |
| 1231 | 968 | 1.39cm | 1.09cm | 1.33cm | 1.36cm | 1.06cm |
| 2152 | 957 | 1.28cm | 1.36cm | 1.28cm | 1.27cm | 1.38cm |
| 2015 | 947 | 1.27cm | 1.12cm | 1.23cm | 1.2cm | 1.11cm |
| 1046 | 946 | 1.24cm | 0.97cm | 1.07cm | 1.07cm | 0.97cm |
Analysis
Since the Google split has frames of each individual in both the sets, it results in very low errors on the 10 individual dataset, as compared to the MIT split. Google uses this version, and quite possibly this is the reason that their mean errors are very low (0.46±0.03cm)
App
Data was collected using an Android App. The users’ photo was clicked at random times while the circle/dots are appearing on the screen. The centre of the circle is noted as the X,y coordinate and frames were assigned to particular coordinate depending on the time stamp.
An Android app was used to collect the data. At random intervals while the circle/dots were visible on the screen, the users’ photos were clicked. The centre of the circle is noted as the (x,y) coordinate of the gaze and frames were assigned to that particular coordinate depending on the time stamp.
New Learnings
- Learning and implementing the network in Tensorflow
- Getting accustomed to training a network on HPC clusters
- Using Comet-ml for hyperparameter tuning and model version tracking
- Visualizing the outputs and interpreting them
- Loading and preprocessing on large datasets
Future Scope and Improvements
- Understanding if we are querying the Google model binary correctly.
- Understanding the SVR patterns in different model versions and find out how well our model is generalizing.
- Training the model with normalization function used by Google.
- Test the model on the phone data collected by our own app, and compare with Google’s binary.
- Comparing with different implementations such as iTracker to see whether the model can be further improved by extending the network.
- While fitting and testing the SVR on the Google split version, some of those points are leaked. This has to be cleaned up in future work.
References
1. Eye Tracking for Everyone
K.Krafka*, A. Khosla*, P. Kellnhofer, H. Kannan, S. Bhandarkar, W. Matusik and A. Torralba
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2. Accelerating eye movement research via accurate and affordable smartphone eye tracking
Valliappan, N., Dai, N., Steinberg, E., He, J., Rogers, K., Ramachandran, V., Xu, P., Shojaeizadeh, M., Guo, L., Kohlhoff, K. and Navalpakkam, V.
Nature communications, 2020
Acknowledgements
I would like to thank my mentors Dr. Suresh Krishna and Mr.Dinesh Sathia Raj for their guidance in every aspect of this project. This work would not have been possible without their support.